滿意度測量和Likert 量表是兩回事
取自洪永泰「社會科學統計方法」上課講義
…由於等第尺度的各個衡量刻度通常都用1,2,3,4,5等數據來表示,許多使用者直接將這些數據當作比率尺度的數字使用,造成誤用統計分析的後果。典型的例子如滿意度的分析,如果題目選項是1非常不滿意,2不滿意,3普通,4滿意,5非常滿意,正確的處理方法應該是視為類別資料,如果是單一變數描述則列出各個選項的百分比;如果是探討和別的選項的關係則使用交叉列表。比較常見的處理是將選項合併成為正面意見、中間意見、負面意見三大類,或者是轉換成另一個變數,例如正面與非正面,或是負面與非負面,都是二分類,這樣做比較方便後續與其他變數關係的探討。
滿意度調查的問卷設計現在比較流行先問正負面態度再續問強弱度的作法。這樣做的好處是將中間意見的反應人數儘可能壓縮,通常也可以得到很好的效果。資料分析時直接以類別資料處理,通常只有正面和負面兩類加上少數無反應,不會有誤用為數字資料的困擾。
滿意度的資料分析通常是單題處理,每一個題目都可以單獨做分析。如果要加總好幾個題目時要特別小心,正確的作法應該是計算同一個受訪者在m個題目之中有幾題回答正面意見,而不是m題去加總12345的答案,這樣做會扭曲選項代碼的意義。
等第資料的另一個常見的典型是Likert 量表。這個量表是加總量表,因發明者而得名。Likert 量表主要是用題組來測量抽象概念,每一題都是一個敘述,請受訪者針對這個敘述回答同意的程度,從很低到很高,通常是3到7個刻度。量表不會是單題存在,一定是題組的形式。早期Likert的設計是將受訪者對題組內所有題目的回答刻度加總,所以稱之為加總量表。然後用這個加總得分來表示受訪者在這個概念的狀態指標。後來因素分析盛行之後也證實了受訪者的因素得點和這個加總分數相當接近。這也使得這個量表的效度和信度更加穩固,使用了快要一百年了還歷久不衰。
壹、資料的性質和資料分析
一、統計分析的兩大領域
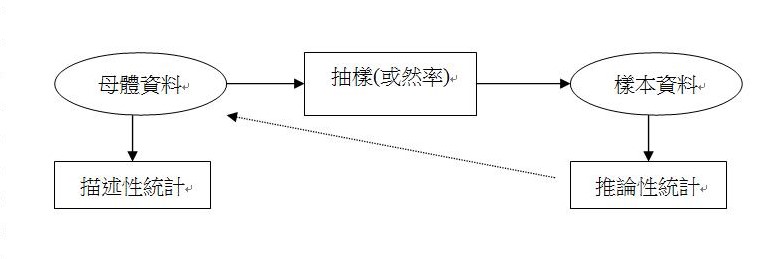
二、資料的性質
(一)依取得方式分
|
資料性質 |
特徵 |
推論效度 |
例子 |
|
觀察性資料 |
順其自然(不改變自然世界) |
相關分析 |
民意調查、田野調查 |
|
實驗性資料 |
操縱自然(改變自然世界) |
因果分析 |
廣告效果測試、新藥測試 |
1.資料的性質會影響推論效度,如果觀察性資料之間存有時間先後的關係,經常會被用來當作推論因果關係的依據,但仍有爭議。
例:社會流動—父母的社經地位vs.子女的社經地位
社會學者認為兩者之間有因果關係,但統計學者則認為只有相關關係,因為資料並不是實驗性資料。
例:抽煙與癌症的關係只能說是有相關關係,不能說是有因果關係,除非進行實驗。
經過一些辯論之後,暫時有一些共識:
以觀察性資料要推論因果關係至少要具備以下三個條件:
(1)變數之間有明確的先後關係,如父母的社會經濟地位在前,子女的在後。
(2)發生在前的變數對發生在後的變數解釋變異量很高。
(3)沒有其他的解釋變數。
2.社會科學的資料大部分都是屬於觀察性的,較難從事控制性、實驗性的研究,因為可能牽涉到倫理的問題。
3.生物醫學研究中有運用入選機率調整法(propensity scores adjustment, PSA)將觀察性資料應用到因果關係的推論,不過條件是必須有另外一組可靠的實驗組數據。這個方法的原理是在將兩組資料混合之後,利用模式分析可預測某些觀察個案是否 包含於實驗組的機率值(propensity scores, PS),此機率值以配對、平均或其他方法分為多個分群,每一分群均分別包含了一定數目的實驗組與控制組個案,透過比較實驗組與控制組在每一分群之權重的調整對實驗效果進行推估(Cochran, 1968; Rosenbaum and Rubin, 1983; Rosenbaum and Rubin, 1984; Rosenbaum, 2005)。
(二)依蒐集範圍分
1.普查資料(母體資料)—所得到的數據是母體參數值(population parameters),可直接進行描述分析,不需做假設檢定,也不需要統計推估,例如投開票所資料、人口普查資料、銀行客戶交易紀錄。
2.抽樣資料(樣本資料)—所得到的數據是樣本統計值(sample statistic),統計推估有理論上的限制,必須先做假設檢定(如t檢定或F檢定),例如民意調查。
(三)依衡量方式分
1.類別資料(categorical data)—分類、計質、間斷性,依資料性質再決定展示工具。
(1)名義尺度(nominal data)—純分類,無大小和強弱之區分,例如性別、地區。
(2)等第尺度(ordinal data)—有大小和強弱之分,但無確定的「量」,例如名次排序、教育程度、滿意度測量、Likert量表等。
2.數字資料(quantitative data)—計量、連續性,內涵的資訊和解釋力較高。
(1)區間尺度(interval data)—“0”沒有定義、無共同的計量基礎點,例如溫度80度並非是40度的2倍、智商為0不表示沒有智商。現實世界中,此類資料並不多。
(2)比率尺度(ratio data)—“0”有明確定義,表示「沒有」的意思,可進行數學四則運算,例如分數、身高、體重。
由於等第尺度的各個衡量刻度通常都用1,2,3,4,5等數據來表示,許多使用者直接將這些數據當作比率尺度的數字使用,造成誤用統計分析的後果。典型的例子如滿意度的分析,如果題目選項是1非常不滿意,2不滿意,3普通,4滿意,5非常滿意,正確的處理方法應該是視為類別資料,如果是單一變數描述則列出各個選項的百分比;如果是探討和別的選項的關係則使用交叉列表。比較常見的處理是將選項合併成為正面意見、中間意見、負面意見三大類,或者是轉換成另一個變數,例如正面與非正面,或是負面與非負面,都是二分類,這樣做比較方便後續與其他變數關係的探討。
滿意度調查的問卷設計現在比較流行先問正負面態度再續問強弱度的作法。這樣做的好處是將中間意見的反應人數儘可能壓縮,通常也可以得到很好的效果。資料分析時直接以類別資料處理,通常只有正面和負面兩類加上少數無反應,不會有誤用為數字資料的困擾。
滿意度的資料分析通常是單題處理,每一個題目都可以單獨做分析。如果要加總好幾個題目時要特別小心,正確的作法應該是計算同一個受訪者在m個題目之中有幾題回答正面意見,而不是m題去加總12345的答案,這樣做會扭曲選項代碼的意義。
等第資料的另一個常見的典型是Likert 量表。這個量表是加總量表,因發明者而得名。Likert 量表主要是用題組來測量抽象概念,每一題都是一個敘述,請受訪者針對這個敘述回答同意的程度,從很低到很高,通常是3到7個刻度。量表不會是單題存在,一定是題組的形式。早期Likert的設計是將受訪者對題組內所有題目的回答刻度加總,所以稱之為加總量表。然後用這個加總得分來表示受訪者在這個概念的狀態指標。後來因素分析盛行之後也證實了受訪者的因素得點和這個加總分數相當接近。這也使得這個量表的效度和信度更加穩固,使用了快要一百年了還歷久不衰。